Zelin Li
New York University Shanghai
Biography
Hi there, I am Zelin Li! Currently I am a NYUSH senior majoring in Data Science. I prefer to seek PhD opportunity after my Master study. My research interests include Natural Language Processing, Large Language Models and Data Science. You can email me at zl3611 [at] nyu [dot] edu.
Interests
- Natural Language Processing (NLP)
- Large Language Models (LLM)
- Data Science
- Computer Vision
Education
-
Bachelor of Science, Data Science (AI Track), 2020 ~ 2024
New York University Shanghai, China
-
Study Away Program, Sept 2022 ~ June 2023
New York University
Working Experience
NLP LLM Research Intern
Responsibilities include:
- Leveraged generated SFT data to complete two downstream fine-tuning tasks on our lab’s medical InternLM (20B), focusing on condensing patient queries and answering questions using an LLM linked to the databases.
- Applied MinHash algorithm to reduce data duplication, improving the quality of medical SFT data for fine-tuning
- Utilized DeepSpeed and ZeRO-2 for accelerated training, and optimized hyperparameters using metaheuristic algorithms to achieve normal convergence.
- Innovatively proposed a “Self-checking” prompt template that, upon implementation, across various tasks throughout the group, reduced average error-induced loss by approximately 6%.
Algorithm Engineer Intern
Responsibilities include:
- Engineered features and preprocessed real-life complaint-related customer insurance data from the company using One-Hot encoding and Pandas.
- Spotted an emerging trend in customer complaints on the “Accidental Injury Insurance” product, implementing LightGBM with suitable hyperparameters to classify customer complaints based on insurance features.
- Evaluated model’s performance using confusion matrix and precision, recall, and AUC-ROC metrics; the results revealed a high F1 of 0.87 and accuracy of 86.1% to successfully predict potential customer complaints and help reduce economic losses through precautionary measures, such as proactively contacting potential complainers.
Data Analyst Intern
Responsibilities include:
- Independently cleaned 200,000 real-life customer data objects from our database to be suitable for analysis; successfully used Python’s Numpy and Pandas packages for exploratory data analysis, utilizing Seaborn and Matplotlib to visualize the characteristics of insurance buyers.
- Identified key predictors of purchase intent for an insurance product: Leveraging Pearson Correlation Coefficient and Spearman’s Rank Correlation, revealing a 0.87 correlation between customer age and purchase likelihood.
- Conducted Chi-Squared Tests to validate key demographic variables, finding a 95% confidence level in the association between customer income bracket and product preferences.
Projects
*
AAAI 2024 Accepted, 2nd Author, Supervised by Prof. Jiafeng Li, East China Normal University
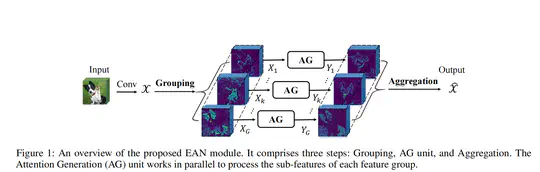
- Innovatively propose an Efficient Attention module guided by Normalization (EAN), a plug-and-play module investigating the intrinsic relationship between feature normalization and attention mechanisms to enhance model efficiency and accuracy across various visual tasks.
- Integrated EAN with an Attention Generation (AG) unit to derive attention weights using parameter-efficient normalization and guide the network to capture relevant semantic responses while suppressing irrelevant ones. The AG unit harnesses the strengths of normalization and attention and combines them into a unified module to enhance feature representation.
- Successfully achieved exceptional performance of the EAN module across multiple disciplines, including Image Classification and Object Detection. Particularly in Object Detection, EAN outperformed the original ResNet50 and MobileNeXt by 5.5% and 5.4% in the MS COCO dataset, validating the superior accuracy and convergence of our EAN compared to state-of-the-art methods.
Planned Submission to ACL 2024, 1st Author, Supervised by Prof. Xiaofan Zhang, Shanghai AI Lab
- Identified a new research task in the information retrieval part of RAG, filling the existing gap by focusing on utilizing multi-turn dialogues as queries to effectively search for the best document in a specific database.
- Built a new dataset for the task: collected medical multi-turn dialogues and retrieved medical docs with them from the lab’s medical database, integrating medical InternLM (20B) to rank docs by model perplexity.
- Pioneered a Graph Convolutional Network (GCN) approach and designed an innovative graph structure: dialogue turns as nodes and syntactic trees (N-LTP) as edges, capturing key information from the dialogues. Optimized the web search vector and calculated similarity between enhanced vector and the vectors of docs derived from BERT.
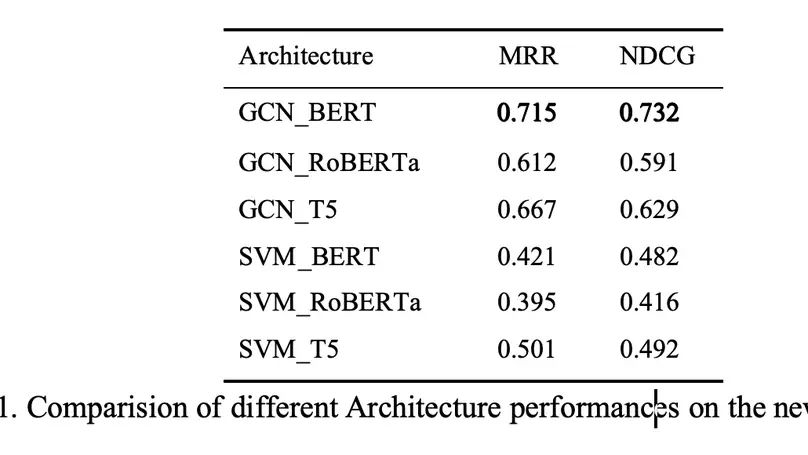
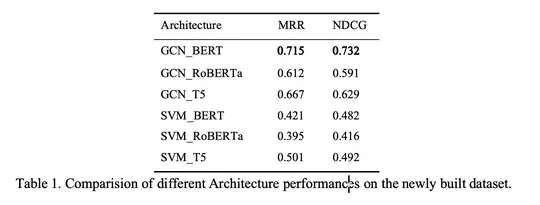
- Achieved an impressive MRR at 0.71, and NDCG at 0.73 as baseline based on 7,500 manually annotated dialogues, showing the model’s reliable accuracy in retrieving the most suitable document from the database.
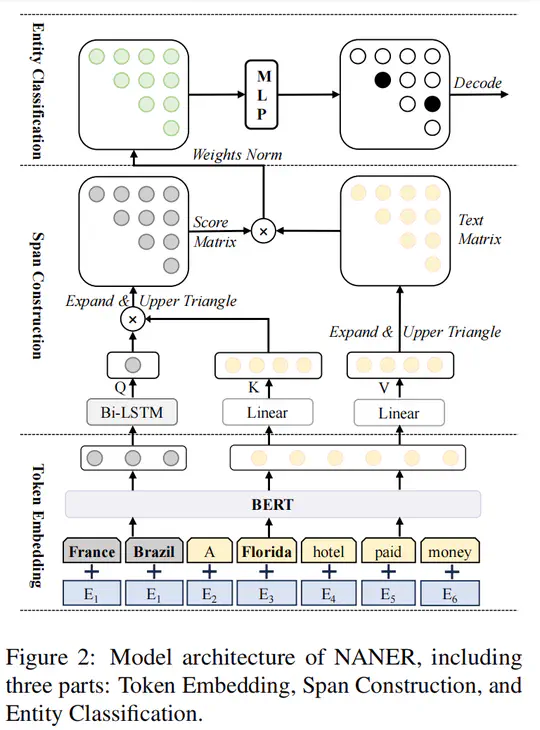
- Proposed NANER, an NER model that utilized instance-based prompt learning to resolve issues related to category ambiguity and the complexity of obtaining high-quality descriptions.
- Employed an instance-based span model named NASpan within NANER, constructing spans with complete tokens, guided by specific entity instances sampled from training sets or online sources like Wikipedia.
- Verified the robustness of NANER by achieving state-of-the-art F1 improvements on datasets such as ACE04, ACE05, and GENIA. NANER also excelled in domain transfer tasks through zero & few-shot learning, enhancing F1 of 11.13% on CoNLL03 and 8.59% on Wnut17 compared to description-based zero-shot benchmarks.